Test-driven development for scientists
Introduction
In Three essential tips for improving your scientific code I talked about the importance of writing tests for your scientific code base. Tests provide a means to verify that new code does what it is intended to do and a means to alert you if you inadvertently break an existing piece of functionality when modifying the code base.
Furthermore, if you have a well tested code base you feel less scared of making changes to it. Whilst coding have you ever thought to yourself:
I could really do with re-writing this to make it simpler, but I'm not sure what else I would break....
If your code base had better test coverage you would not feel this way. Having tests give you the ability to make sweeping changes to the code whilst retaining confidence that you have not broken any vital piece of functionality.
Tests also provide a type of living documentation of your code base, a specification of how the code is intended to work.
In fact tests are so important that some people write them before they write any code in a method known as test-driven development.
In this post we will make use of the skills we built up in Four tools for testing your Python code to explore test-driven development. We will use test-driven development to create a Python FASTA parser package.
What is test-driven development?
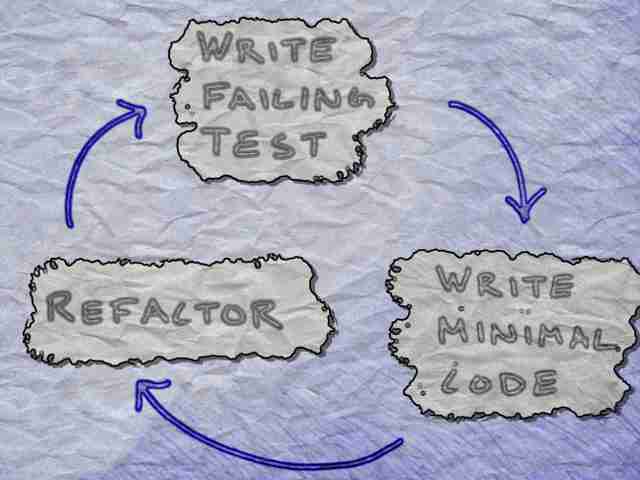
Test-driven development, often abbreviated as TDD, can be thought of as a three step process.
- Write a test for the functionality that you have in mind and watch it fail
- Write minimal code to make the test pass
- Refactor the code if required
Don’t worry if the above sounds a bit abstract. The purpose of the rest of this post is to illustrate how this works in practise.
What are the benefits of test-driven development?
The three main reasons I love test-driven development are:
- It makes me think about how I want my code to behave up front
- It makes me write tests
- It is fun
Of course I could write tests after having implemented a piece of code. However, in practise when I code first and test later, the “test later” rarely happens.
This may sound silly, but it is not much fun writing a test for something that already works. It feels like a menial task. On the other hand, writing a test before an implementation exists stimulates my brain, I have to think about how I want my code to behave.
Furthermore, a failing test is like a challenge. In writing a failing test I am giving myself a tiny puzzle to solve. The test-driven development cycle essentially gamifies my working day, with the positive side-effect of producing an extensive test suite.
For a more exhaustive list of benefits of test-driven development have a look at Mark Levison’s post: Advantages of TDD.
If you are interested in this topic I also recommend reading Kane Mar’s three part post: The benefits of TDD are neither clear nor are they immediately apparent.
Spiking
It is not wrong to develop code without tests. However, if you are doing test-driven development you should treat such exploratory code as “throw away” and use it as a guide to write tests when doing things properly. In this context “properly” means writing the tests first. People who practise test-driven development refer to such exploratory coding as a spike. Here we will treat the exploration from the prevoius FASTA post as a spike.
Creating a project template
We will start by creating a project template using cookiecutter
$ cookiecutter gh:tjelvar-olsson/cookiecutter-pypackage
...
repo_name (default is "mypackage")? tinyfasta
version (default is "0.0.1")?
authors (default is "Tjelvar Olsson")?
...
$ cd tinyfasta
And setting up a clean Python development environment.
$ virtualenv ~/virtualenvs/tinyfasta
$ source ~/virtualenvs/tinyfasta/bin/activate
(tinyfasta)$ python setup.py develop
Note that you can view this project and its progression on GitHub.
Start with a functional test
When practising test-driven development it is often useful to start with a functional test. A functional test differs from a unit test in that it tests a slice of functionality in the system as opposed to an individual unit. The rational for starting with a functional test is that it allows us to take a step back and think about the larger picture.
We can translate the learning from our spike into a functional test. The code
below parses FASTA records from the dummy.fasta file and writes the records
to another file tmp.fasta. The test then ensures that the contents of the
two files are identical.
def test_output_is_consistent_with_input(self):
from tinyfasta import FastaParser
input_fasta = os.path.join(DATA_DIR, "dummy.fasta")
output_fasta = os.path.join(TMP_DIR, "tmp.fasta")
with open(output_fasta, "w") as fh:
for fasta_record in FastaParser(input_fasta):
fh.write("{}\n".format(fasta_record))
input_data = open(input_fasta, "r").read()
output_data = open(output_fasta, "r").read()
self.assertEqual(input_data, output_data)
Here is a link to the input FASTA file tests/data/dummy.fasta.
Start building up functionality using unit tests
Another reason for starting with a functional test is that it can act as a
guide for what to implement. When we run the functional test we immediately
find out that we need a class named FastaParser.
Traceback (most recent call last):
File "/Users/olssont/junk/tinyfasta/tests/tests.py", line 31, in test_output_is_consistent_with_input
from tinyfasta import FastaParser
ImportError: cannot import name FastaParser
At this point we add a unit test for initialising a FastaParser instance.
def test_FastaParser_initialisation(self):
from tinyfasta import FastaParser
fasta_parser = FastaParser('test.fasta')
self.assertEqual(fasta_parser.fpath, 'test.fasta')
After having run the test and watched it fail we add minimal code to make the unit test pass.
class FastaParser(object):
"""Class for parsing FASTA files."""
def __init__(self, fpath):
"""Initialise an instance of the FastaParser."""
self.fpath = fpath
The implementation makes the unit test pass. So we continue by running the functional test again.
Traceback (most recent call last):
File "/Users/olssont/junk/tinyfasta/tests/tests.py", line 40, in test_output_is_consistent_with_input
for fasta_record in FastaParser(input_fasta):
TypeError: 'FastaParser' object is not iterable
Okay, so we need a test to make sure that the class is iterable.
def test_FastaParser_is_iterable(self):
from tinyfasta import FastaParser
fasta_parser = FastaParser('test.fasta')
self.assertTrue(hasattr(fasta_parser, '__iter__'))
At this point it may be worth reflecting on how we should make this test pass. In test-driven development we want to add minimal implementation to get the tests to pass. The code below is pretty minimal and it makes the test pass.
def __iter__(self):
"""Yield FastaRecord instances."""
yield None
As the docstring above suggests we want the FastaParser to yield
FastaRecord instances. So at this point we can start building up the
FastaRecord class using small incremental steps of test and code. To get a
feel for this have a look at the commits:
- cd34f8b Added FastaRecord class.
- ef95643 Added sequence logic to FastaRecord.
- 873798b Added string representation of FastaRecord class.
At this point we have all the functionality we need to add a proper
implementation of the FastaParser.__iter__() method, which we hope will
make the functional test pass.
def __iter__(self):
"""Yield FastaRecord instances."""
fasta_record = None
with open(self.fpath, 'r') as fh:
for line in fh:
if line.startswith('>'):
if fasta_record:
yield fasta_record
fasta_record = FastaRecord(line)
else:
fasta_record.add_sequence_line(line)
yield fasta_record
Let us make sure that all the tests pass.
$ nosetests
........
Name Stmts Miss Cover Missing
-----------------------------------------
tinyfasta 26 0 100%
----------------------------------------------------------------------
Ran 8 tests in 0.027s
OK
Great we have a basic working implementation of our tinyfasta.py module.
And iterate
Now that we have the basics implemented we want to add more functionality and by now you know what that means: another test. As we are wanting to add new functionality we start all over again with another functional test.
In the commit history of the tinyfasta project one can see how
functionality for searching the FASTA description line was added.
- fb685cb Added functional test for FastaRecord.description_matches search.
- cd78c02 Added empty description_matches function.
- 1b89336 Added description_matches implementation.
Followed by functionality for searching the biological sequence.
- 5fe617d Added functional test for FastaRecord.sequence_matches function.
- e97e623 Added empty sequence_matches function.
- 4f27704 Added sequence_matches implementation.
Refactoring
Up until this point we have followed the work flow below
- Write a test
- Write minimal code to make the test pass
However, this is not the whole story as it leaves out an important aspect of test-driven development: refactoring.
Let us start with a simple example of factoring out code duplication. After having added functionality for using either strings or compiled regular expressions to search the description and sequence we notice that there is a lot of code duplication.
def description_matches(self, search_term):
"""Return True if the search_term is in the description."""
if hasattr(search_term, "search"):
return search_term.search(self.description) is not None
return self.description.find(search_term) != -1
def sequence_matches(self, search_motif):
"""Return True if the motif is in the sequence.
:param search_motif: string or compiled regex
:returns: bool
"""
if hasattr(search_motif, "search"):
return search_motif.search(self.sequence) is not None
return self.sequence.find(search_motif) != -1
As we have been using test-driven development we have tests for all the functionality of interest. We can therefore refactor the code to the below.
@staticmethod
def _match(string, search_term):
"""Return True if the search_term is in the string.
:param string: string to be searched
:param search_term: string or compiled regex
:returns: bool
"""
if hasattr(search_term, "search"):
return search_term.search(string) is not None
return string.find(search_term) != -1
def description_matches(self, search_term):
"""Return True if the search_term is in the description.
:param search_term: string or compiled regex
:returns: bool
"""
return FastaRecord._match(self.description, search_term)
def sequence_matches(self, search_motif):
"""Return True if the motif is in the sequence.
:param search_motif: string or compiled regex
:returns: bool
"""
return FastaRecord._match(self.sequence, search_motif)
And run the tests.
$ nosetests
......................
Name Stmts Miss Cover Missing
-----------------------------------------
tinyfasta 43 0 100%
----------------------------------------------------------------------
Ran 22 tests in 0.032s
OK
As all the tests pass we can have some level of confidence that everything is still working as intended.
Improving the design of the code
At some point whilst documenting how to use the tinyfasta package I realised that
the function names description_matches and sequence_matches were a little bit
misleading and that the names description_contains and sequence_contains would
be more appropriate. This was a relatively simple change to make, see
commit 0496373.
However, some time later I realised that it would be much nicer if the API of the
tinyfasta package would allow code that looked like the below. Note that the
description is no longer a function, but an instance of some sort which has
a contains function.
>>> from tinyfasta import FastaParser
>>> for fasta_record in FastaParser("tests/data/dummy.fasta"):
... if fasta_record.description.contains('seq1'):
... print(fasta_record)
...
>seq1|contains 2x78 A's
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Although, the change to the feel of the API is minor (an underscore swapped for
a full stop), the change to the underlying behaviour of the tinyfasta
package is major.
However, because of all the tests the change was not so hard to implement.
First I went into the tests and changed all the calls to the
description_contains and sequence_contains to description.contains
and sequence.contains. Then I simply “listened to my tests” as they guided
me through all the changes that needed to be made for the package to become
functional again. Have a look at
commit 7fb248f
to see the resulting changes to the code base.
Conclusion
I hope this post inspires you to try out test-driven development. However, don’t be surprised if you find that it is harder than it looks. Like everything it requires practise. If you feel really stuck, try using a spike to get you going and then use the resulting code to inspire a functional test.
I can also highly recommend Harry Percival’s book Test-Driven Development with Python. It is what inspired me to start using test-driven development.
Happy coding!